Project
Starling Data
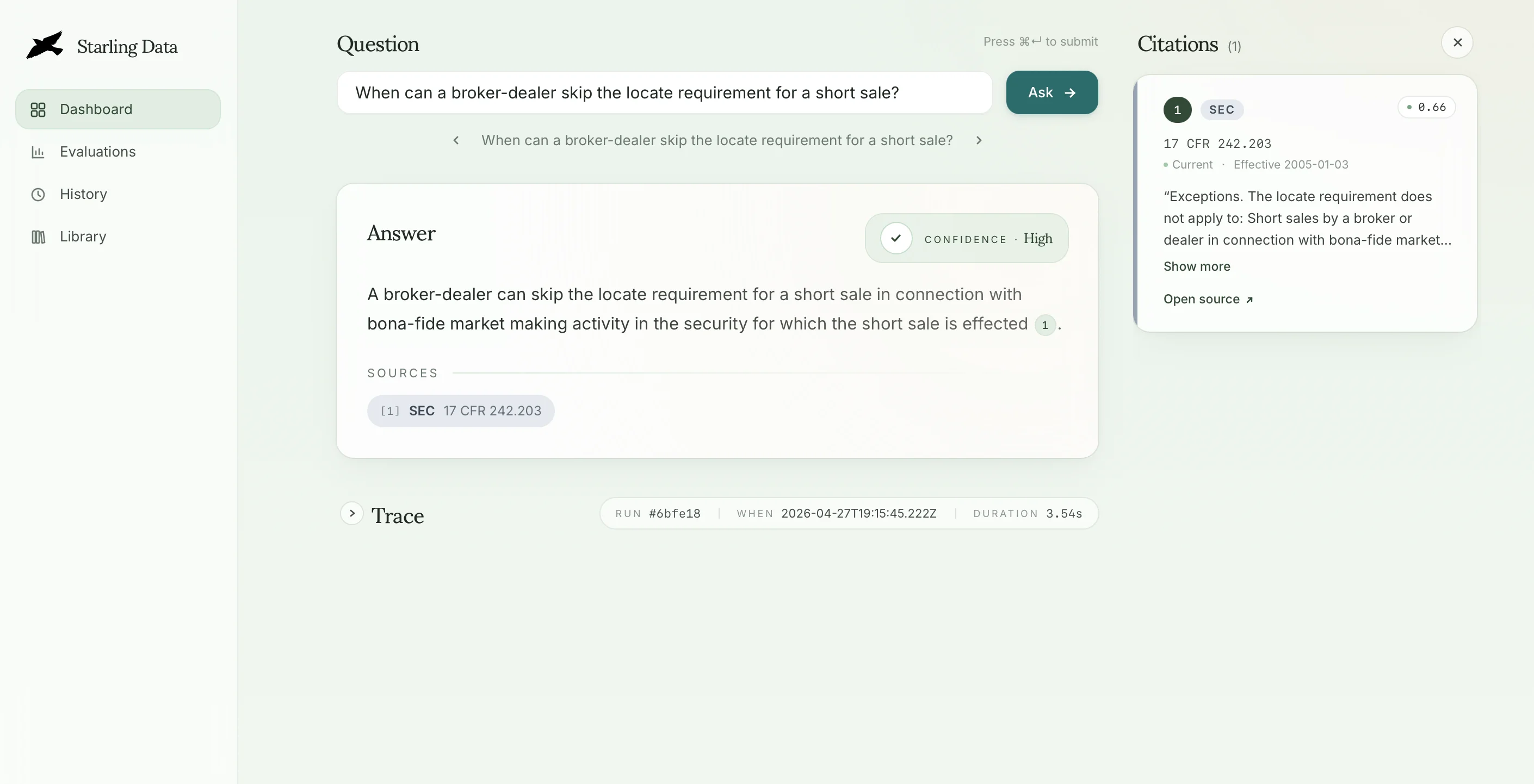
Adaptive RAG compliance copilot for financial institutions with grounded, source-cited answers
Compliance teams at banks, credit unions, and lenders work against a sprawling and shifting body of regulation — federal rules, state-by-state variation, examiner guidance, and the institution's own internal policies layered on top. Traditional search returns documents and leaves the interpretation to a human; asking a general-purpose LLM risks confident fabrication or stale citations, neither of which survives an exam. Starling Data is a product built to close that gap. It's an adaptive RAG (Retrieval Augemented Generation) copilot that returns grounded answers with inline citations to the underlying source, surfaces confidence rather than hiding it, and refuses to answer when retrieval is insufficient — so every response is defensible and auditable.
Under the hood it's a LangGraph StateGraph (retrieve → generate) wired into a Next.js app, with markdown-aware chunking, OpenAI embeddings, and a Pinecone vector store. The architecture is intentionally shaped so future jobs — multi-hop cross-reference analysis, agentic exam preparation with human-in-the-loop review, plain-language interpretation, and recency-sensitive change monitoring — slot in as added nodes and conditional edges rather than rewrites. A curated evaluation harness measures retrieval precision, answer faithfulness, and flag accuracy so changes are regression-checked instead of vibes-checked.
- Next.js
- React
- TypeScript
- LangGraph
- LangChain
- OpenAI
- Pinecone
- RAG
- Evaluation Harness
- Vitest
- Playwright
- Agentic Coding
 Starling Data
Starling Data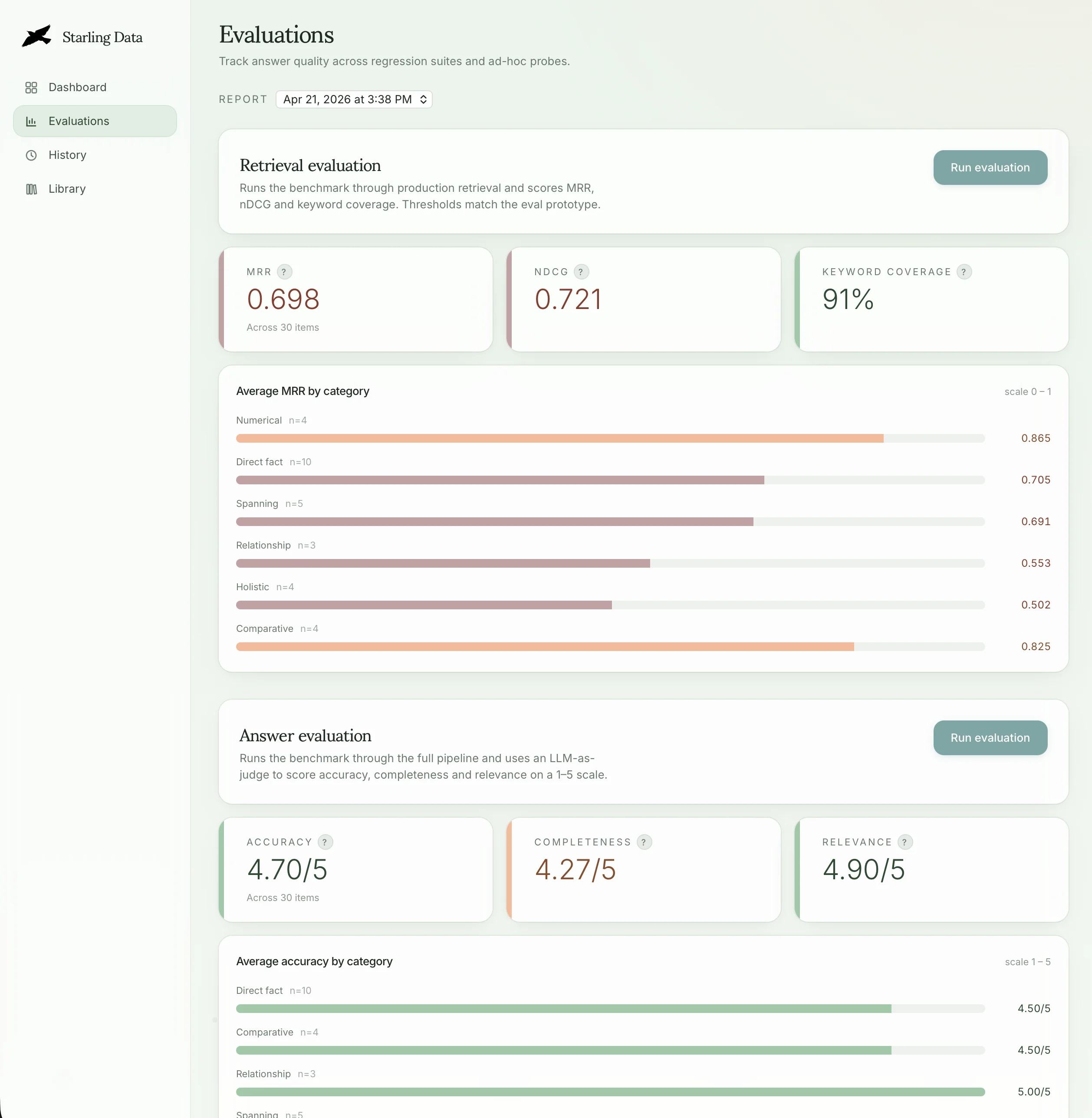 Starling Data
Starling Data